활동 목표: LG Aimers 강의 4차 정리
활동 결과:
1. 개요
기존 계획에 따르면, 현재 열리고 있는 LG Aimers라는 대회의 준비 과정인 강의를 수강한 후 정리하는 것이었지만
벌써 대회가 시작되고 많은 시간이 지나버렸다...!
그래서 대회의 기반 모델인 EXAONE 4.0 1.2B 모델을 하나하나 파헤쳐보기 위한 EXAONE 4.0 논문 리뷰를 진행하려고 했다!
따라서 대회의 주제인 EXAONE 모델 경량화를 위해 EXAONE 모델의 레이어 구조를 뜯어보고 다양한 양자화 기법들에 대한 이야기를 하겠다.
2. EXAONE 4.0 1.2B
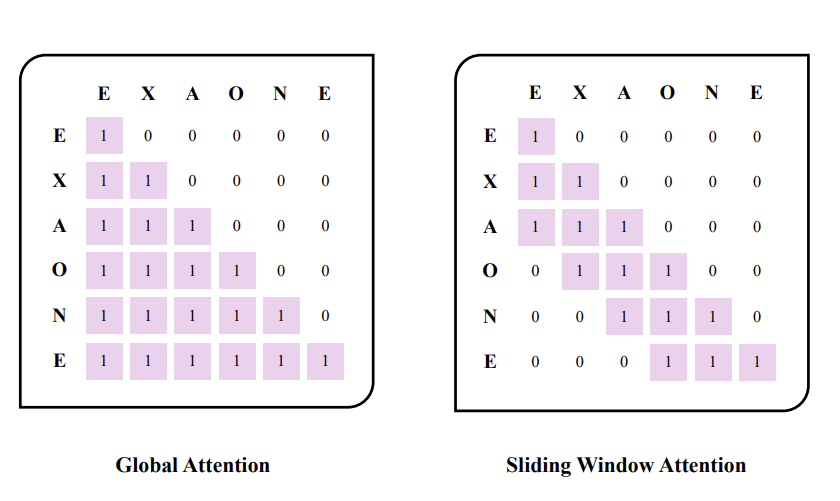
EXAONE 모델은 Sliding window를 사용하는 Hybrid Attention 구조이다.
EXAONE 모델은 거대한 32B 모델과 on-device로 사용하기 위해 작은 1.2B모델이 있는데
이번 대회에서 사용하는 1.2B모델은 Global Attention만 사용하기 때문에 이에 대해서 자세히 알 필요는 없다고 언급되었다.
하지만 궁금하죠??
2.1. Hybrid Attention
기존의 모든 문장을 보는 Global Attention은 연산량이 O(n²)이기 때문에 문장이 길어질수록 비효율적이다.
이를 보완하기 위해 일부는 Global Attention을 취하되, 일부는 Local Attention으로 전체 문장이 아닌 주변 문맥만 확인하도록 한다.
EXAONE 모델은 이 Local Attention을 Sliding Window Attention으로 사용했는데
Sliding Window Attention은 기존의 컴퓨터 공학에서 많이 사용되는 Sliding Window를 떠올리면 이해하기 쉬울 것이다.
query가 이동하면서 자신 주변 단어만 확인하는 Attention 기법이다.
2.2. QK-Reorder-LN
이 구조는 쉽게 설명하면 기존의 Attentiojn 과정 사이에 Layer Normalization, 즉 Reorder 를 진행하는 것이다.
그리고 이 Normalization은 RMSNorm을 사용했다.

이러한 구조를 사용하는 이유는, 기존의 Transformer 구조에서 어떤 문제가 있는지 알아야 한다.
기존의 Transformer의 구조(2회차 transformer paper 참고)는 Post-LN 구조로 Attention block을 통과한 후 Norm을 진행했다.
이러한 Post LN 구조를 더욱 안정성 있도록 만든 것이 Pre-LN 구조이다. Norm을 더욱 앞당겨 기울기를 더욱 완만하게 만들었다.
하지만 Pre-LN 구조는 레이어가 깊어지게 되면 residual connection로 인해 층이 깊어질수록 분산이 커지게 된다.
그리하여 LN을 Reorder한 것이 QK-Reorder-LN 구조인 것이다.

2.3. Model configuration
다음과 같다.

3. Mixed precision
지금까지 모델의 레이어 구조에 대해 알아보았다.
이를 분석한 이유는 이번 해커톤에서 소개한 양자화 기법이 Mixed precision이기 때문이다.
Mixed precision이란 모델의 각 레이어마다 다른 정도의 양자화를 진행하는 것이다.
모델에서 중요한 레이어의 경우에는 양자화를 진행하지 않거나 크기를 조금만 줄이고
비교적 중요하지 않은 레이어의 경우에는 양자화를 통해 크기를 크게 줄이는 방식이다.
이 방향성으로 EXAONE에 대해 더욱 깊게 파헤쳐보며 대회를 진행해 나가도록 하겠다!
'모각코' 카테고리의 다른 글
| [2026 동계 모각코] 모각코 회고 (0) | 2026.02.18 |
|---|---|
| [2026 동계 모각코] 5회차 활동 결과 - LLM Agent (0) | 2026.01.30 |
| [2026 동계 모각코] 4회차 활동 결과 - Decoding, RAG (0) | 2026.01.24 |
| [2025 동계 모각코] 3회차 활동 결과 - Fine tuning과 Domain Adaptation (0) | 2026.01.12 |
| [2026 동계 모각코] 2회차 활동 결과 - Transformer 제대로 이해하기 (0) | 2026.01.07 |