활동 목표: Transformer 제대로 이해하기
활동 결과:
1. 개요
이번 글에서는 transformer에 대해 배경, 개념 등을 설명하기보다는
transformer의 구조를 보면서 각각 어떤 process를 거치는지 파헤쳐 보도록 하겠다.
2. transformer 구조
transformer 하면 바로 떠오르는 이미지는 "Attention Is All You Need" 라는 매우 유명한 논문의 아키텍쳐이다.

이제부터 이 아키텍쳐를 하나하나 뜯어보도록 하겠다.
2.1. Embedding과 Positional Encoding
Embedding이란 무엇인가?

이전에 멀티모달 임베딩에 대해 만든 자료가 있어서 첨부한다.
단어에 대해 임베딩을 진행하면 각 단어가 벡터로 표현되고 벡터 사이의 각도가 작을수록 큰 유사도를 띄게 된다.
따라서 벡터의 내적을 진행한 뒤 크기로 나누면 코사인 값이 나오게 되는데, 각도가 작을수록 이 값이 1에 가깝고 반대 방향일 경우 값이 -1이 나온다. 이를 코사인 유사도라고 한다.
Positional Encoding이란 단어의 위치 정보를 알려주는 것이다.
단어마다 인덱스를 부여하는 방식을 떠올릴 수 있는데 이 방법은 학습했던 값보다 인덱스가 커지면 모델의 일반화 성능에 문제가 생긴다. 그래서 이를 0과 1 사이로 정규화한다면 각 인덱스 값의 차이가 input의 크기에 따라 달라져 문제가 생긴다.
그래서 positional embedding은 다음과 같은 방식으로 문제를 해결한다.

인덱스를 유지하며 인덱스 값의 차이를 phase를 도입하며 일정하게 유지시키는 방식을 사용한다.
본문에서 조금 벗어났지만 단어의 위치 정보를 알려주는 개념으로 기억하면 된다.
2.2. 인코더
이후 인코더의 multi-head-attention으로 들어간다.
이를 이해하기 이전에 attention에 대한 이해가 선행적으로 필요하다.
2.2.1. Scaled Dot-Product Attention
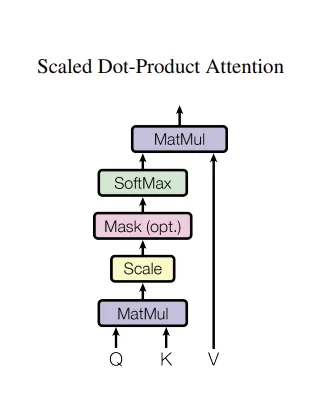
Q, K, V는 입력 문장에 대한 단어 벡터로 이들의 유사도를 통해 어떤 단어에 집중할지를 결정한다.
간단히 설명하면 각각의 행렬곱(내적)으로 유사도를 계산하는 것이다.
Q, K, V는 모든 입력 문장에 대한 정보이며, Q가 의미하는 바는 t 시점 단어의 정보이고 K는 전체 시점 단어의 정보, V는 전체 시점 단어의 의미이다.
따라서 Q와 K를 내적해 t시점에 유사한 단어의 의미를 찾아 V와 내적을 통해 가중치의 합을 구한다.
이러한 attention 매커니즘에 scaling과 masking을 추가한 것이 Scaled Dot-Product Attention 이다.
여기서의 masking은 의미가 없는 토큰(padding)을 masking하는 것이다.
추후 나올 Masked Multi-Head Attention에서의 masking과 헷갈릴 수 있기에 부연설명하였다.
scaleing은 아래 root(d_k)로, softmax로 들어가기 전의 값을 조절해준다.

2.2.2. Multi-Head Attention
Multi - Head Attention은 위에서 진행한 Scaled Dot-Product Attention 과정을 여러 개의 head로 나누어 독립적으로 진행하는 것이다.
여러 개의 head로 나누어 Scaled Dot-Product Attention을 진행하면 더욱 풍부한 정보를 획득할 수 있다.
문장 내에서 각 단어가 가지는 여러가지 의미를 생각하지 않고 하나에만 집중되어 편향되는 것이 아니라 여러 가지 의미를 파악할 수 있도록 한다.
2.2.3 Add & Norm
Add 는 residual connection 을 의미한다. 이는 입력과 출력을 더해주는 것으로 성능 저하를 막아준다.
Norm 은 이 더해진 값을 다시 정규화해 다음 입력으로 넘겨준다.
2.2.4. Feed Forward
Feed Forward 는 차원을 늘려 활성화 함수를 거치고 다시 차원을 내려서 반환한다.
중요한 정보의 손실을 막기 위해 차원을 늘리고 낮추는 과정을 진행하는 것으로 이해하면 된다.
이를 다시 Add & Norm 을 거쳐 인코더에서 나오게 된다.
2.3. 디코더
디코더의 입력을 보면 특이하게 생겼다.
Outputs(shifted right)는 shifted right를 통해 output의 이전 단어를 보고 다음 단어를 예측한다.
2.3.1. Masked Multi-Head Attention
Masked Multi-Head Attention은 Multi-Head Attention에 t 시점 이후는 정보를 지워(mask) 현재 시점 이후를 모르는 상태로 학습을 진행하는 것이다.
2.3.2. Cross Attention
아키텍쳐에 Cross Attention이라는 단어가 없는데요?
이 부분이 Cross Attention이다.
Corss Attention은 인코더에서 나온 Q, K, V와 디코더에서 계산 중인 Q, K, V를 연결해준다.
Cross Attention에서의 Attention 연산은 인코더의 K, V값을 가져와 디코더의 Q를 사용해 계산한다.
그리하여 인코더에서(전체 문장, 이전 단어에서)의 K, V를 가져와 mask한 디코더의 Q와 Attention을 진행하는 것이다.
2.4. Linear, Softmax
2.4.1. Linear Layer
Linear는 디코더에서 나온 output vector를 Logit vector로 변환시킨다.
여기서의 Logit vector는 output vector를 단어들에 대한 확률값으로 변환한 vector이다.
따라서 이 과정을 unembedding이라고도 한다.
unembedding matrix와의 행렬곱을 통해 vocab의 단어들과의 유사도를 구하는 것이다.
2.4.2. Softmax와 temperature
이 유사도를 softmax를 거쳐 확률값으로 변환해 가장 높은 확률을 출력…하는 것이 아니라
temperature에 따라 temperature가 낮을수록 높은 확률을 더 높게, 낮은 확률을 더 낮게 만들고
temperature가 높을수록 높은 확률을 낮게, 낮은 확률은 상대적으로 높아지게 만든다.
temperature이라는 하이퍼파라미터를 통해 생성의 무작위성을 정할 수 있는 것이다.
지금까지 transformer의 구조를 하나하나 뜯어 보았다.
사실 하나하나 뜯어보았다기에는 부끄러운 내용이다.
한 글로 정리하기에 무리가 있는 내용이었고, 설명이 미흡한 부분이 너무나도 많다.
transformer를 인공지능에 대한 지식이 없는 사람도 알 수 있는 글을 써보고 싶었는데 이번 글은 엉망진창이다…
추후 여러 개의 글로 transformer를 정리해서 올려보도록 하겠다.
'모각코' 카테고리의 다른 글
| [2026 동계 모각코] 4회차 활동 결과 - Decoding, RAG (0) | 2026.01.24 |
|---|---|
| [2025 동계 모각코] 3회차 활동 결과 - Fine tuning과 Domain Adaptation (0) | 2026.01.12 |
| [2026 동계 모각코] 1회차 활동 결과 - 인공지능 코드 실습하기 (0) | 2026.01.01 |
| [2026 동계 모각코] 모각코 활동 계획 (0) | 2026.01.01 |
| [2025 하계 모각코] 모각코 회고 (1) | 2025.08.17 |